SERVIDOR DE INFERENCIA NVIDIA TRITON
El Servidor de Inferencia NVIDIA Triton™ es un software de servicio de inferencia de código abierto que ayuda a estandarizar la implementación y ejecución de modelos y ofrece IA rápida y escalable en producción.
EMPEZAR¿Qué es NVIDIA Triton?
El Servidor de Inferencia Triton agiliza la inferencia de IA al permitir que los equipos implementen, ejecuten y escalen modelos de IA capacitados desde cualquier framework en cualquier infraestructura basada en GPU o CPU. Brinda a los investigadores de IA y a los científicos de datos la libertad de elegir el framework adecuado para sus proyectos sin afectar el despliegue de producción. También ayuda a los desarrolladores a ofrecer inferencias de alto rendimiento en dispositivos en el cloud, en las instalaciones, edge e integrados.
Compatibilidad con Diversos Frameworks
El Servidor de Inferencia Triton es compatible con todos los principales frameworks como TensorFlow, NVIDIA® TensorRT™, PyTorch, MXNet, Python, ONNX, RAPIDS FIL (para XGBoost, scikit-learn, etc.), OpenVINO, C++ personalizado y más.
Inferencia de Alto Rendimiento
Triton es compatible con todas las inferencias basadas en CPU NVIDIA GPU, x86 y ARM®. Ofrece funciones como procesamiento por lotes dinámico, ejecución concurrente, configuración óptima del modelo, conjunto de modelos y entradas de transmisión para maximizar el rendimiento y la utilización.
Diseñado para DevOps y MLOps
Triton se integra con Kubernetes para orquestación y escalado, exporta métricas de Prometheus para monitoreo, admite actualizaciones de modelos en vivo y se puede usar en todas las principales plataformas de IA en el Cloud y Kubernets. También está integrado en muchas soluciones de software MLOPS.
Acelere Su Viaje de IA con NVIDIA LaunchPad
Experimente el Servidor de Inferencia Triton y otro software de IA de NVIDIA a través de laboratorios seleccionados gratuitos en infraestructura alojada.
Integraciones del Ecosistema con NVIDIA Triton
La IA está impulsando la innovación en empresas de todos los tamaños y escalas. Una solución de software de código abierto, Triton es la mejor opción para la inferencia de IA y la implementación de modelos. Triton es compatible con Alibaba Cloud, Amazon Elastic Kubernetes Service (EKS), Amazon Elastic Container Service (ECS), Amazon SageMaker, Google Kubernetes Engine (GKE), Google Vertex AI, HPE Ezmeral, Microsoft Azure Kubernetes Service (AKS) y Azure Machine Learning. Descubra por qué las empresas utilizan Triton.
Recursos de Inferencia de IA de NVIDIA

Simplifique la Implementación de IA a Escala
Simplifique la implementación de modelos de IA a escala en producción. Aprenda cómo Triton enfrenta los desafíos de implementar modelos de IA y revise los pasos para comenzar.
DESCARGAR LA DESCRIPCIÓN GENERAL
Ver Sesiones on Demand
Ver sesiones on demand en Servidor de Inferencia Triton de NVIDIA GTC.
VER AHORA
Implemente Modelos de Deep Learning de IA
Obtén las últimas noticias y actualizaciones, y obtén más información sobre los beneficios clave en el Blog Técnico de NVIDIA.
LEER BLOGS
Leer la Documentación del Producto
Vea las novedades y obtenga más información sobre las funciones más recientes en las notas de la versión de Triton.
LEER EN GITHUBIA Rápida y Escalable en Cada Aplicación
El Servidor de Inferencia NVIDIA Triton ofrece un alto rendimiento de inferencia:
Triton ejecuta múltiples modelos del mismo o diferentes frameworks al mismo tiempo en una sola GPU o CPU. En un servidor multi-GPU, Triton crea automáticamente una instancia de cada modelo en cada GPU para aumentar la utilización.
También optimiza el servicio para la inferencia en tiempo real bajo estrictas restricciones de latencia, admite la inferencia por lotes para maximizar la utilización de GPU y CPU, y la inferencia de streaming con soporte integrado para entrada de streaming de audio y video. Triton admite conjuntos de modelos para casos de uso que requieren múltiples modelos para realizar inferencias de un extremo a otro, como la IA conversacional.
Los modelos se pueden actualizar en vivo en producción sin reiniciar Triton o la aplicación. Triton permite la inferencia de múltiples GPU y múltiples nodos en modelos muy grandes que no caben en una sola memoria de GPU.

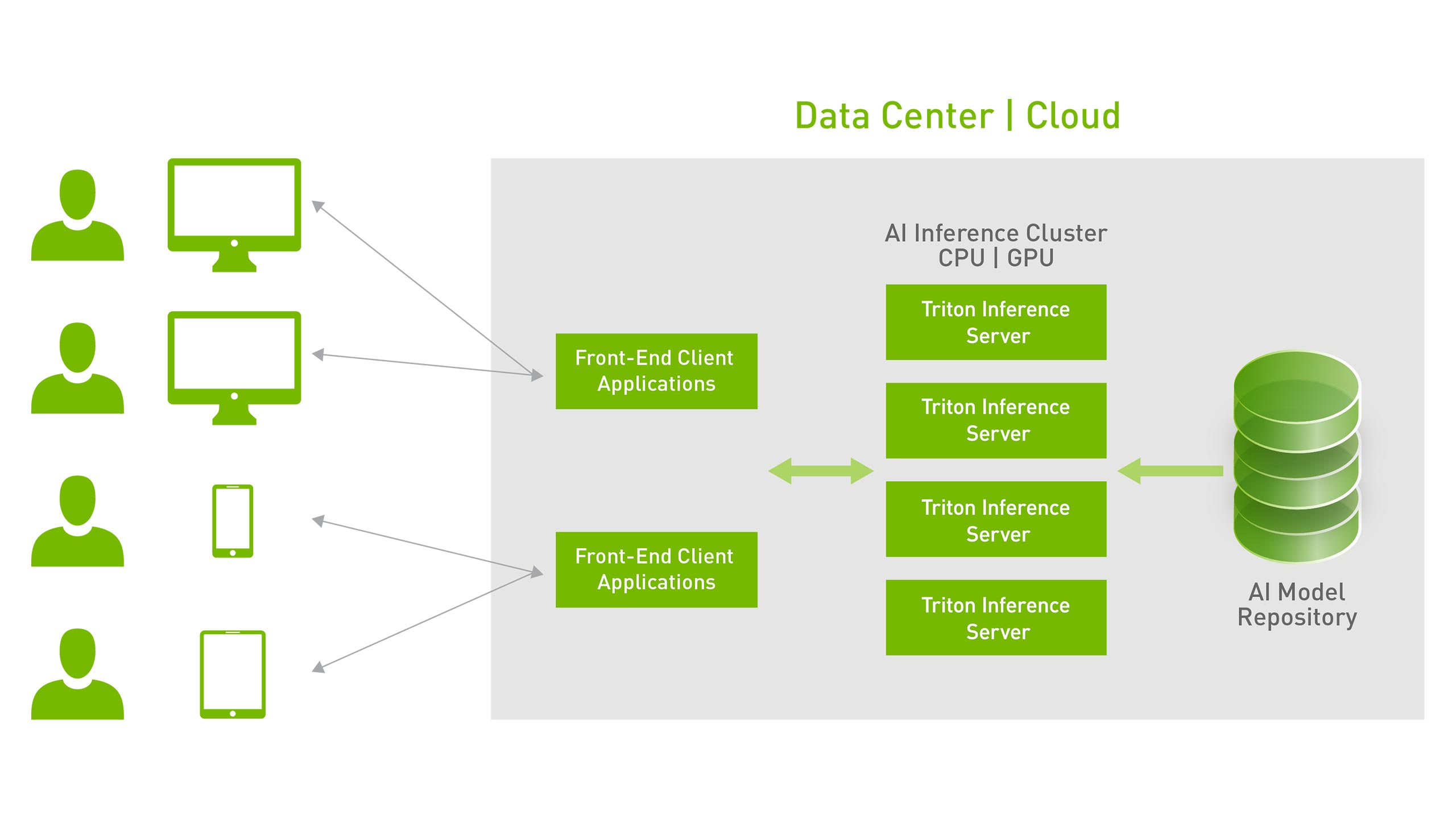
El Servidor de Inferencia NVIDIA Triton ofrece una inferencia altamente escalable:
También disponible como contenedor Docker, Triton se integra con Kubernetes para orquestación, métricas y escalado automático. Triton también se integra con Kubeflow y pipelines de Kubeflow para un workflow de IA de extremo a extremo y exporta métricas de Prometheus para monitorear la utilización de GPU, la latencia, el uso de memoria y el rendimiento de inferencia. Admite la interfaz HTTP/gRPC estándar para conectarse con otras aplicaciones, como balanceadores de carga, y puede escalar fácilmente a cualquier cantidad de servidores para manejar cargas de inferencia crecientes para cualquier modelo.
Triton puede servir decenas o cientos de modelos a través de una API de control de modelos. Los modelos se pueden cargar y descargar dentro y fuera del servidor de inferencia en función de los cambios para que quepan en la memoria de la GPU o la CPU. La compatibilidad con un clúster heterogéneo con GPU y CPU ayuda a estandarizar la inferencia entre plataformas y escala dinámicamente a cualquier CPU o GPU para manejar las cargas máximas.
Características Clave de Triton
Back-end de la Forest Inference Library (FIL) de Triton
El nuevo backend Forest Inference Library (FIL) brinda soporte para la inferencia de alto rendimiento de modelos basados en árboles con explicabilidad (valores de Shapley) en CPU y GPU. Admite modelos de XGBoost, LightGBM, scikit-learn RandomForest, RAPIDS cuML RandomForest y otros en formato Treelite.
Servicio de Gestión Triton
El Servicio de Gestión Triton (TMS) aborda el desafío de escalar de manera eficiente las instancias de Triton con una gran cantidad de modelos. TMS es un servicio que ayuda cuando hay más modelos de los que pueden caber en una sola GPU y cuando se necesitan muchas instancias de Triton en los servidores para manejar las solicitudes de inferencia de diferentes aplicaciones.
Próximamente
Analizador de Modelos Triton
El Analizador de Modelos Triton es una herramienta para evaluar automáticamente las configuraciones de implementación de Triton, como el tamaño del lote, la precisión y las instancias de ejecución simultánea en el procesador de destino. Ayuda a seleccionar la configuración óptima para cumplir con las restricciones de calidad de servicio (QoS) de la aplicación: requisitos de latencia, rendimiento y memoria. Reduce el tiempo necesario para encontrar la configuración óptima de semanas a horas.
Programa de NVIDIA para Startups
NVIDIA Inception es un programa gratuito diseñado para ayudar a las startups a evolucionar más rápido a través del acceso a tecnología de punta como NVIDIA Triton, expertos de NVIDIA, capitalistas de riesgo y soporte de marketing conjunto.
MÁS INFORMACIÓN
También puede descargar el Servidor de Inferencia Triton en NGC. Si está interesado en el soporte empresarial, obtenga más información sobre NVIDIA AI Enterprise.