ディープラーニング ソフトウェア
NVIDIA CUDA-X AI は、研究者やソフトウェア開発者が、対話型 AI、レコメンダー システム、コンピューター ビジョン向けの高性能な GPU アクセラレーション アプリケーションを構築するための完全なディープラーニング ソフトウェア スタックです。CUDA-X AI ライブラリは、MLPerf などのさまざまな業界ベンチマークにおいて、トレーニングと推論の両方で世界をリードするパフォーマンスを発揮しています。
TensorFlow、PyTorch、 JAX をはじめ、すべてのディープラーニング フレームワークは、シングル GPU でのアクセラレーションに対応しており、マルチ GPU やマルチノードの構成によるスケールアップも可能です。フレームワークの開発者や研究者は、GPU に最適化された CUDA-X AI ライブラリの柔軟性を利用して、新しいフレームワークやモデル アーキテクチャを高速化できます。
CUDA-X をベースとする NVIDIA の統合プログラミング モデルにより、デスクトップやデータセンターでディープラーニング アプリケーションを開発して、データセンター、リソースに制約のある IoT デバイス、自動車プラットフォームに最小限のコード変更で展開できます。
NVIDIA® NGC™ カタログ では、一般的なディープラーニング モデル向けの学習済みモデル、トレーニング スクリプト、最適化されたフレームワーク コンテナー、推論エンジンを提供しています。NVIDIA AI Toolkit には、学習済みモデルの転移学習、微調整、最適化、展開のためのライブラリが含まれており、幅広い業界や AI ワークロードに対応しています。
NVIDIA Github には、各種の製品、デモ、サンプル、チュートリアルの 100 を超えるリポジトリがあるため、すぐに始められます。

あらゆるフレームワークとの統合
ディープラーニング フレームワークは、高度なプログラミング インターフェイスからディープ ニューラル ネットワークを設計、トレーニング、検証するためのビルディング ブロックを提供します。PyTorch や TensorFlow、JAX などの広く使用されるディープラーニング フレームワークで cuDNN や TensorRT などの GPU アクセラレーション ライブラリを利用することにより、GPU で高速化されるハイパフォーマンスなトレーニングや推論を実現できます。
NGC では、最新の GPU に最適化され、CUDA ライブラリおよびドライバーと統合されたコンテナー化されたフレームワークを提供しています。毎月のリリースの一環として検証とテストが実施されており、さまざまなエッジやクラウド プラットフォームで最高のパフォーマンスが得られるようになっています。フレームワークとの統合、リソース、サンプルの詳細を確認して、利用を開始するには、ディープラーニング フレームワークのページをご覧ください。

ディープラーニング トレーニング
CUDA-X AI ライブラリは、あらゆるフレームワークにおけるディープラーニング トレーニングを加速させます。その高性能な最適化により、対話型 AI、自然言語理解、レコメンダー システム、コンピューター ビジョンなどのさまざまなアプリケーションで、GPU による世界トップクラスのパフォーマンスを実現しています。最新の GPU 性能は、ディープラーニング トレーニング パフォーマンスのページでいつでもご確認いただけます。
GPU アクセラレーション フレームワークを使用すると、Tensor コアでの混合精度演算などの最適化により、さまざまな種類のモデルを高速化できるほか、シングル GPU 上のトレーニング ジョブを、数千もの GPU から成る DGX SuperPOD にスケーリングするのも簡単です。
ディープラーニングが言語理解や対話型 AI といった複雑なタスクに適用されるようになるにつれ、モデルのサイズとそのトレーニングに必要なコンピューティング リソースが爆発的に増大しています。一般的なアプローチでは、汎用的なデータセットで事前にトレーニングされたモデルから開始し、特定の業界、ドメイン、ユース ケースに合わせて微調整を行います。NVIDIA AI ツールキットでは、学習済みモデルから開始して転移学習や微調整を行うためのライブラリやツールを提供しているため、独自の AI アプリケーションの性能と精度を最大限に高めることができます。

Data Loading Library (DALI) は、GPU アクセラレーションを利用したデータ拡張および画像読み込みライブラリです。ディープラーニング フレームワークのデータ パイプラインを最適化できます。
詳細を見る

CUDA Deep Neural Network (cuDNN) は、畳み込み、活性化関数、テンソル変換のためのディープラーニング プリミティブなど、ディープ ニューラル ネットワーク アプリケーション用のビルディング ブロックを備えた高性能ライブラリです。
詳細を見る
NVIDIA Collective Communications Library (NCCL) は、all-gather、reduce、broadcast などのルーチンにより、最大 8 基まで拡張可能なマルチ GPU 通信を高速化します。
詳細を見る
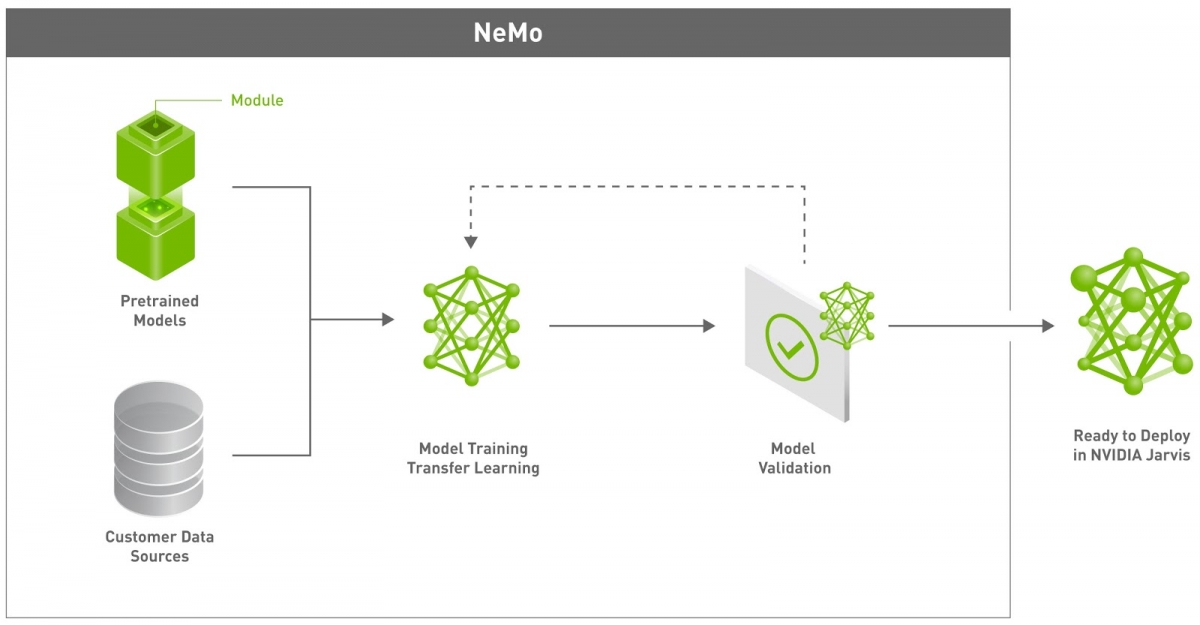
NVIDIA Neural Modules (NeMo) は、AI アクセラレーションを利用した音声および言語アプリケーションのた��の最先端のニューラル ネットワークを構築できるオープンソース ツールキットです。
詳細を見る

TAO ツ��ルキット は、AI のトレーニングを高速化するための Python ベースのツールキットで、学習済みモデルの最適化や転移学習の適用により、高い精度を実現できます。学習済みモデルは、DeepStream SDK や TensorRT を使用することで NVIDIA エッジ プラットフォーム上で効率的にプルーニングして展開できるため、高性能 AI システムの構築が可能です。
詳細を見る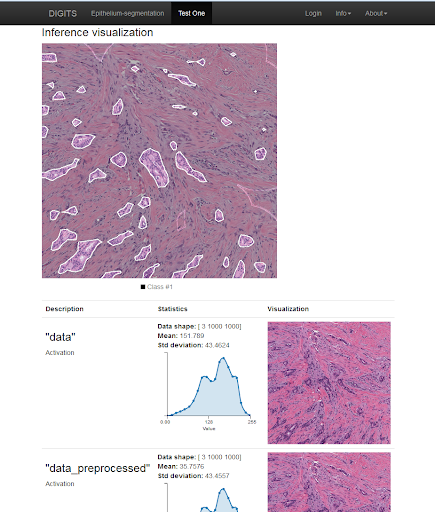
NVIDIA Deep Learning GPU Training System (DIGITS) は、データの管理、マルチ GPU システムのコンピューター ビジョン ネットワークの設計とトレーニング、リアルタイムのパフォーマンス監視が可能なインタラクティブなツールで、展開用に最適なパフォーマンスのモデルを選別できます。
詳細を見る
ディープラーニング推論
CUDA-X AI には、コンピューター ビジョン、対話型 AI、レコメンダー システム などのアプリケーションを運用環境 で実行する際に、レイテンシを最小限に抑え、スループットを最大限に高める ことができる高性能ディープラーニング推論 SDK が含まれています。NVIDIA の推論 SDK で開発されたアプリケーションは、CPU のみのプラットフォームと比較して、GPU による最大 40 倍の推論性能を実現できます。
CUDA 統合プラットフォームをベースにして構築された NVIDIA の CUDA-X 推論ソリューションは、デスクトップ上で任意のフレームワークを用いてモデルを開発し、最適化を適用して、推論用にデータセンターおよびエッジに簡単に展開できます。
対話型 AI やレコメンダー システムのアプリケーション パイプラインでは、顧客からの問い合わせ 1 件あたり 20 ~ 30 個のモデルを実行し、それぞれのモデルで数百万のパラメータを処理します。アプリケーションの応答性が高いと感じられるようにするには、このパイプラインを 300 ミリ秒未満で完了する必要があり、各モデルに非常に厳しいレイテンシ要件が課されます。高性能の最適化と 低精度の推論 (FP16 や INT8) を用いると、GPU では他のプラットフォームよりも 大幅に高いパフォーマンスを得ることができます。
最新の GPU 性能は、ディープラーニング推論パフォーマンスのページでいつでもご確認いただけます。
TensorRT を用いた CNN での推論画像分類
ResNet-50 v1.5 のスループット
DGX-1: NVIDIA V100-SXM2-16GB x 1、E5-2698 v4 2.2 GHz | TensorRT 6.0 | バッチ サイズ = 128 | 19.12-py3 | 精度: 混合 | データセット: Synthetic
Supermicro SYS-4029GP-TRT T4: NVIDIA T4 x 1、Gold 6240 2.6 GHz | TensorRT 6.0 | バッチ サイズ = 128 | 19.12-py3 | 精度: INT8 | データセット: Synthetic
ResNet-50 v1.5 のレイテンシ
DGX-2: NVIDIA V100-SXM3-32GB x 1、Xeon Platinum 8168 2.7 GHz | TensorRT 6.0 | バッチ サイズ = 1 | 19.12-py3 | 精度: INT8 | データセット: Synthetic
Supermicro SYS-4029GP-TRT T4: NVIDIA T4 x 1、Gold 6240 2.6 GHz | TensorRT 6.0 | バッチ サイズ = 1 | 19.12-py3 | 精度: INT8 | データセット: Synthetic

NVIDIA TensorRT は、高性能ディープラーニング推論用 SDK です。ディープラーニング推論向けのオプティマイザーとランタイムが含まれており、ディープラーニング推論アプリケーションにおける低レイテンシ、高スループットを実現します。
詳細を見る
NVIDIA Triton Inference Server はオープン ソースの推論ソフトウェアで、GPU 使用率を最大化する DL モデルを提供します。Kubernetes と統合されており、オーケストレーション、メトリクス収集、自動スケーリングが可能です。
詳細を見る

NVIDIA Riva は、視覚、音声、その他のセンサーを融合した AI アプリケーションの構築と展開のための SDK です。ジェスチャーや視線などの視覚的な手がかりをコンテキスト内の音声と共に使用できる GPU アクセラレーション AI システムを構築、トレーニング、展開するための完全なワークフローを提供します。
詳細を見るNGC カタログの学習済みモデルと DL ソフトウェア
The NVIDIA® NGC™ カタログは、ィープラーニングと機械学習のための GPU 最適化ソフトウェアのハブです。AI ソフトウェアは毎月更新され、ワークステーション、オンプレミス サーバー、エッジ、クラウド上の GPU 搭載システムに簡単に展開できるコンテナーを通じて提供されます。学習済みモデルとモデル スクリプトも揃っており、開発者は自らのデータセットで独自のモデルをすばやく構築できます。さらに、業界固有のニーズに対応する AI ソリューションを構築するための SDK と、ソフトウェアの展開を容易にする Helm レジストリも用意されており、計算時��を短縮できます。
NGC™ カタログの目的は、AI ソフトウェアへのアクセスを容易にして、データ サイエンティストや開発者が AI ソリューションの構築に集中できるようにすることです。



NVIDIA® NGC™ カタログでは、ディープラーニング モデル作成の手順とスクリプトのほか、結果を比較できるように性能と精度のサンプル指標も提供しています。これらのスクリプトは、無駄のない高精度のモデルを構築するためのベスト プラクティスを活用しつつ、高い柔軟性も備えているため、ユース ケースに合わせてモデルを自在にカスタマイズできます。
詳細を見る
開発者/DevOps 向けツール
NVIDIA の開発者向けツールはデスクトップやエッジ環境で動作し、ディープラーニング、機械学習、HPC アプリケーションにおける複雑な CPU と GPU の利用に関する独自のインサイトを提供します。これにより、開発者はアプリケーションの構築、デバッグ、プロファイリング、パフォーマンスの最適化を効果的に行えます。Kubernetes on NVIDIA GPU を使用すれば、企業はトレーニングや推論の展開環境をマルチ GPU クラスターにシームレスに拡張できます。
Nsight Systems は、アプリケーションのアルゴリズムを可視化するために設計された、システム全体を対象としたパフォーマンス分析ツールです。最大限の最適化が可能な部分を特定し、CPU や GPU の数や規模に関係なくスケーリングを効率的に調整できます。
DLProf (Deep Learning Profiler) は、GPU の使用率、Tensor コアでサポートされている操作、実行中の Tensor コアの使用状況を可視化するプロファイリング ツールです。
Kubernetes on NVIDIA GPU を利用すると、企業はトレーニングと推論の展開環境をマルチクラウド GPU クラスターにシームレスにスケールアップできます。開発者は、GPU アクセラレーション アプリケーションを依存関係と一緒に 1 つのパッケージにまとめ、Kubernetes で展開し、展開環境を問わず NVIDIA GPU 上で最高のパフォーマンスを実現できます。
Nsight Compute は、CUDA を使用して直接構築されたディープラーニング アプリケーションのためのインタラクティブなカーネル プロファイラです。GUI またはコマンド ライン インターフェイスから、詳細なパフォーマンス指標を確認したり、API のデバッグを行ったりできます。また、Nsight Compute のデータ駆動型のユーザー インターフェイスはカスタマイズ可能で、提供される指標コレクションは、結果の後処理用の分析スクリプトで拡張可能です。
FME (Feature Map Explorer) を使用すると、低レベルのチャネル視覚化や、特徴マップの完全なテンソルおよび各チャネル スライスに関する詳細な数値情報など、さまざまなビューで 4 次元の画像ベースの特徴マップ データを視覚化できます。